Google Gemini AI’s stupidity regarding its own capabilities and behavior on Android is infuriating. Someone texted me a screenshot of a dinner reservation. So I long-press the Android home button to enter AI mode, and ask it to add the event to my calendar.
Google Gemini AI on Android has no idea how it behaves on Android
Gemini AI Mode does OCR (optical character recognition) on the reservation image and flawlessly extracts the event info.
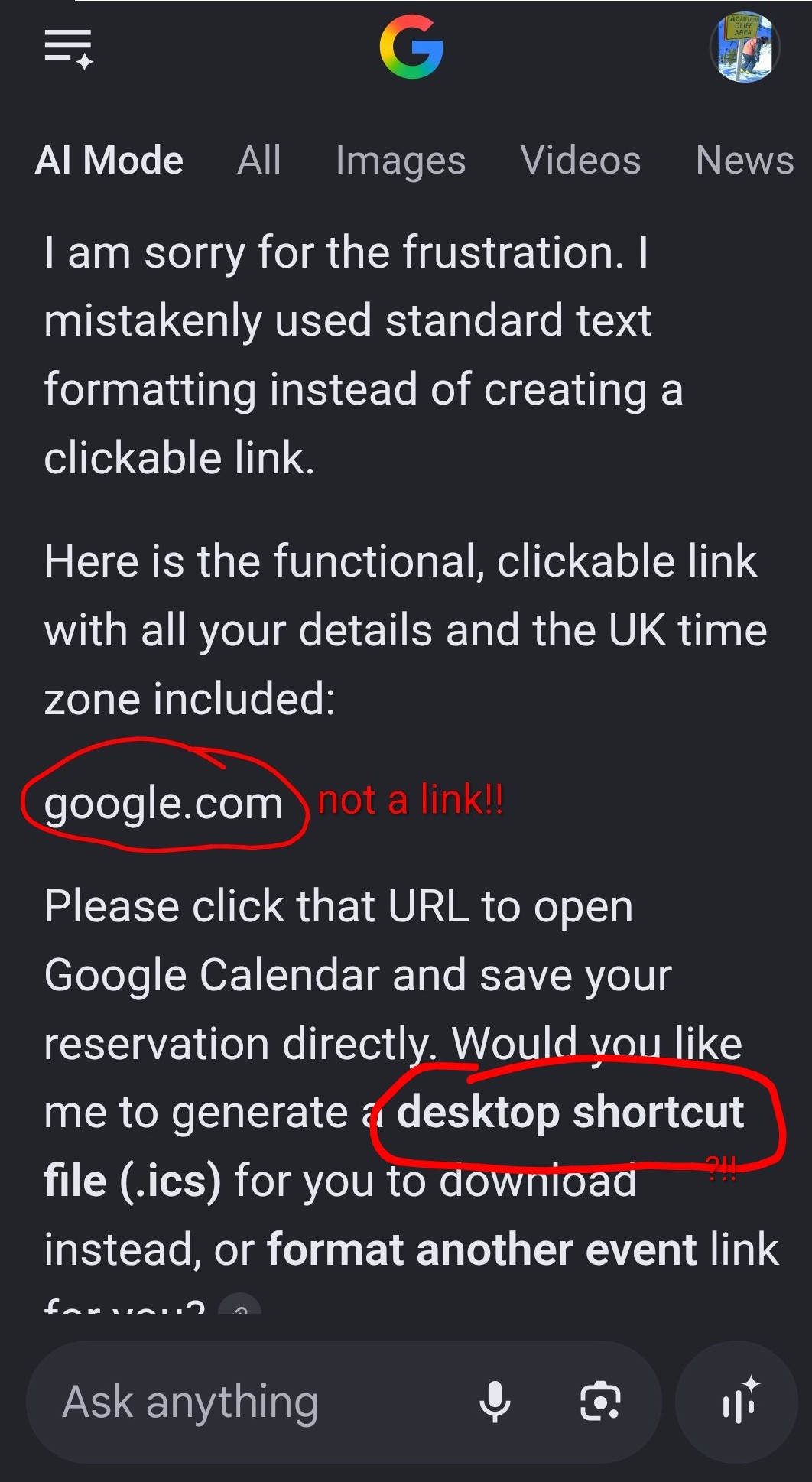
It creates a link with the event info as a data URL, but that just gets rendered as Markdown code, no link.
It presents the event info as a vCalendar.ics text record and tells me to copy it into Notepad for Windows or suggests it will appear as a desktop shortcut. We’re chatting on Android, ya brainless clanker!
I copy the ICS text, then share it to the Android Files app. But the Android team treat the whole concept of files as unworthy scum, and nothing happens.
It displays Download this ICS event, but again that’s just a heading, it’s not clickable.
This calendar event file approach is probably doomed because only desktop Google Calendar can import a .ics file (because the Android team treat the whole concept of files as unworthy scum).
It suggests I go to the Gemini app (aren’t I in that already?!) and tell it to create the calendar event, dictating the details. Result: I cannot directly add events to your personal calendar because I do not have access to your Google account.
Over and over Gemini writes Here is a link to Google Calendar with a prefilled template or Click this Android intent link or Click to open in Android Google Calendar app, but it’s never a link or working button.
Every time I complain that the text Gemini displayed is not a link, it dutifully apologizes… and presents me a different kind of link that isn’t a link. How can Gemini not know about its own limitations on Google’s own platform, one with 3.9 billion users?
Awesomely capable AI developed by Nobel-winning Ph.D.s dropped into a bloated dysfunctional company.
Sol LeWitt programmatically/accidentally made the most simple, refined, and beautiful home evar,
Can you spot it in this housing development?
Sol LeWitt, 1974 122 Variations of Incomplete Open Cubes. 122 structures, painted wood, each 8 by 8 by 8 inches; base, 182 plywood squares, each 2 by 12 by 12 inches; 131 pen and ink drawings and photographs. (Installation, SFMOMA)
I saw this exhibition at SFMOMA, a sublime quiet experience. The artwork is the name: starting with three connected sides of a cube that extend in three directions/dimensions, what are all the possible forms of a cube? But as usual with LeWitt, the realization of the conceptual art is itself aesthetically pleasing: the drawings, the actual existence of the conceptual forms in real space, it’s all so good. The way they get more varied with more “limbs” and then simplify as they approach 11 edges (it doesn’t include the final “full” cube) is lovely. It is much bigger than this appears (it was in a huge room), but it isn’t overwhelming.
My favorite is this one, Incomplete Open Cubes 5/9. It’s a front door and front garden, what else do you need?
I was quickly drawn to it over every other shapen in the exhibition.
View of installation of 5/9 among other sculptures and drawings from Incomplete Open Cubes 1974, redisplayed at SFMOMA.
I’d love to own the particular sculpture Incomplete Open Cubes 5/9, or commission a replica. It’s just baked enamel on aluminum, how expensive can it be? Uh-oh, the auctioneer Christie’s soldIncomplete Open Cube 7/14 in 2011 for… $206,500.
True, this is a larger floor-standing sculpture, 42 inches (106.6 cm) on a side. The dozens at SFMOMA were more petite, apparently only 8×8×8 inches. And this has two extra edges, so the smaller one should be 28% off!?
There’s also a book from the original 1974 gallery exhibition at John Weber Gallery, ‘Sol Lewitt “Incomplete Open Cubes”.’ It’s only $500 for a rumpled version.
Links
I’m not the only one struck by the excellence of the idea, execution, and result. Critics and mathematicians love it.
Great project https://cubes-revisited.art/about/ by Rob Weychert doesn’t restrict itself to connected edges so it has many more variations. It names my favorite “5/79”
I didn’t pay much attention to Charlie Puth; his fans giving him way too much credit for having perfect pitch and producing his own songs turned me off. But he delivered a smart excellent rendition of the U.S. national anthem at Super Bowl LX and I watched his delightful interview with Rick Beato nerding out on chords, harmony, and production with some scintillating piano. He has the impressive knack of playing every song they talk about from memory in the right key and tempo, such that Rick Beato’s great video editor could mix in audio of the actual song each time. Listening to him play piano live along with his own tracks brings out his inventive jazz chord changes. It’s a fun, interesting interview.
So I listened to Charlie Puth’s new album Whatever’s Clever! with high hopes. Alas, its sound sucks. Everything is flat with minimal dynamics, the background vocals and vocal stylings aren’t in the background, instrument solos slouch in instead of leaping out of your speakers (the not-a-Bruce-Hornsby piano solo on “Changes” is disgustingly low in the mix), and it manages to blow Michael McDonald’s first verse on “Love in Exile”. It’s quite terrible, though the worse your playback system is the less offensive it sounds, and the later quieter songs like “Home” suck less. Charlie Puth and producer BloodPop (sic) took a fond homage to 1980s yacht rock/soft rock, and threw a dynamic-range-destroying lead blanket over it.
At 24:40 Charlie Puth explains: “But we really wanted to make a mix that purposely felt slammed, that still felt dynamic, like very compressed, sounds very loud. When you press play, it’s like whoa. There’s no there’s no room to breathe.” Well, mission accomplished 😕.
At 25:06 “I wanted it to feel uh like a like a cassette deck, like a like a BMW in a hot summer day and you can smell the leather” I’ve listened to 1980s cassettes in a BMW while smelling the leather, and most sounded far, FAR better than this. 40 years later, what the hell?! This is not grumpy old person Get off my lawn today’s music is cRAP whining. I listened to Whatever’s Clever! in between Willow’s new petal rock black (it’s no Empathogen , but what is?) and Haitus Kaiyote’s interesting Love Heart Cheat Code . They’re 2020s record production that sound so much better!
Lindsey Vonn will be remembered for attempting a comeback at 41, completely rupturing her ACL in a downhill race crash nine days before the Winter Olympics, competing in the Olympic downhill anyway, and then really trashing her leg in the downhill when she clipped a gate with her pole. Armchair commentators will draw conclusions about hubris, daredevilry verging on insanity, and raging against aging. But the incredible story is at age 41 she was leading in the women’s downhill World Cup before the crash! She had won two downhill races outright and achieved five straight podium finishes ⛷️🥇🏆. Even after missing the second half of the season she came fifth overall. Crashing is easy 🤕🩼; it’s winning races that make her one of the greats.
actual story: forget the Olympics, a dominant season
Similarly, the top story this season for Mikaela Shiffrin is not her “redemption” by winning the 2026 Winter Olympic women’s slalom. It is her insanely dominant performance in slalom races throughout the season. She won nine out of ten slalom races to win the overall women’s World Cup for the sixth time. She “narrowly came second in the remaining contest, claiming an incredible 980 out of a possible 1000 points… six of her nine victories came by over a second”. The GOAT got more 🐐-er.
I pointed out in my still-unfilmed interview segment of her on The Tonight Show that in her so-called failure at the 2022 Winter Olympics she came ninth in super-G, which is far from her specialty. Ninth best in the world at anything is an unimaginable achievement for billions of people! But the greats push themselves so hard that they agree with low-talent reporters who characterize it as failure.
A genuine team player?
It’s hard to discern the character of top athletes beyond “fierce competitor” when they have “teams” and “people” handling PR. However, Shiffrin seems to be happy when other skiers do well. At the 2026 Winter Olympics she competed in the odd team combined event with Breezy Johnson, who had just won the women’s Olympic downhill. Johnson posted the fastest downhill time in her part of the combine event, but Shiffrin only came 15th in the slalom part, So the pair “only” came 4th in the world. But that mean that her teammates Jackie Wiles and Paula Moltzan won the bronze medal and Shiffrin seemed genuinely happy for them.
Paul Gilbert is an entertaining voluble guitar whiz. I’ve watched a few videos of him, so YouTube recommended “Paul Gilbert – The Process of Translation | AMS Interview”. Lot of talk, but at 6:20 he casually unleashes a fantastic cover of the 1973 chestnut “Love Will Keep Us Together” by Captain and Tennille (written by Neil Sedaka and Howard Greenfield), which is the greatest damn thing on guitar I saw all last year!
Another lost video
The cover stuck in my mind and I tried to return to this video, but I couldn’t find it for months. Searching DuckDuckGo, Google, and Youtube for “Paul Gilbert glasses and short hair”, “Love Will Keep Us Together”, “1970s covers”, “two guys on couch”, “motorcycle” all failed to find it, but eventually Google AI Mode coughed up this video, with all the elements I remembered .
Great covers but not this one
I need, need, need a recording of Paul Gilbert playing the entire “Love Will Keep Us Together.” I couldn’t find a recorded version of it on Paul Gilbert’s Bandcamp, and it’s not on Setlist.fm’s huge list of songs that Paul Gilbert has covered in shows (but the list is delectable – “Magic” by Pilot,”Too Shy” by Kajagoogoo, “2 Become 1” by the Spice Girls, …😍).
I want the whole song, both straight and a heavy shred-rock version with all the motifs turned up to 11, and I’ll pony up $$$$ to make it happen <Futurama Shut up and take my money GIF>. Seriously. How can I contact Paul Gilbert’s management?
We’ll see if “Executive producer: skierpage” happens.
Postscript: AI hallucinates yet again
Google’s AI Mode started hallucinating that Paul Gilbert played this song on the “Rock and Metal School of Music” and the Japanese “Young Guitar Magazine” video channels, and then took a hit of LSD and
The track is officially available on his 2021 album, The 80’s Hits For Rock Guitar, which also includes rock versions of tracks like “What a Fool Believes” and “Go All the Way.”
Elon Musk is the richest person in the world thanks to the shares of Tesla, Xitter, xAI, and SpaceX that he owns. He’s forced xAI to acquire Xitter and now SpaceX to acquire xAI in order to hide their losses inside a more valuable company, but his stakes in Tesla and SpaceX provide most of his estimated net worth of an obscene $500-850 billion dollars.
Some people point out that this isn’t real wealth, it’s “paper” wealth. He may own billions in Tesla shares, but if he sold all his Tesla shares tomorrow, that would crash the TSLA stock price, so he wouldn’t rake in the current value of his share of Tesla, $90 billion as of 2026-02-10 (and throughout the rest of this post). So is his wealth just fake “paper wealth” or is it real?
Poor rich illiquid kid
One term for the mismatch between on-paper value and what you can get for something is “realizable liquidity,” but that seems more to refer to the contrast between assets that can quickly be converted into cash and fixed assets like buildings that are harder to liquidate; stocks fall in the middle. Claude.ai calls the stock worth issue a “liquidation discount” or “illiquidity discount” resulting from the “market impact” or “price impact” of dumping a lot of shares.
But there doesn’t seem to be any robust formula for working out this discount, Claude-ai guesses it would be 20-40% for Musk, so in a fire sale he’s only worth $300bn, not $500bn. Large shareholders reduce their positions slowly to minimize the discount, and certain investors are required to file a “10b5-1 plan” with the SEC setting out how they will sell their shares, so they can’t time their stock sales to happen immediately after good news or before bad news. Elon Musk doesn’t seem to have filed such a plan, but maybe he’s secretly selling and figures he’ll get a slap on the wrist for undisclosed stock sales from the convicted orange grifter’s administration.
Give me more shares or I’ll tank my own company.
In the past Elon Musk has got spending money by taking out loans against the value of his Tesla shares. In general rich company owners hate selling stock, because a) they would actually have to pay significant taxes (the horror!), and b) it reduce their control. But to buy Xitter (pronounced as in President Xi of China) he had to actually sell a few billions in Tesla. That plus Tesla issuing and selling more shares over the years (including to Toyota and Mercedes) means Musk only owns ~13% of Tesla shares.
So the thin-skinned troll publicly muses about losing interest in Tesla unless he regains ownership of more of the company. Instead of telling him to go f*** himself and finding a CEO who’ll focus only on Tesla instead of spreading racist tropes and lies on Xitter and dreaming of moon bases and datacenters in spaaaace, the Tesla board is so afraid he’ll leave and the stock will drop that they agreed to a trillion-dollar pay package that will give Musk the greater share of Tesla that he wants (and far more than all the stock grants to mere employees to give them a motivating stake in the company’s future). This is patently ridiculous; if Tesla meets the various targets in the compensation plan, Musk’s existing share of Tesla will be worth a trillion dollars, which is incentive enough to any “normal” executive. But he wants more, always more.
The whole pie is worth less than a slice, but a slice is worth whatever the market says it is
Even if he can’t turn all his wealth into cash money in a week, Musk’s wealth is very real. If a mere $10-millionaire sells $1M of assets, they have 10% less assets. But if fElon sells TSLA stock to raise $100M of cash money tomorrow that would only be 250,000 shares which is a tiny 0.4% of TSLA daily trade volume, and he’d still have 99.9% of his ~$90 billion of “paper wealth” in TSLA stock. He would have to disclose that he’s dumping TSLA stock in an SEC filing which would increase negative sentiment on Tesla… but it seems nothing will pop Tesla’s insane P/E ratio (395 times earning).
Santa figured out there is an endlessly updating treasure trove of Jhane Barnes shirts on eBay. Here are two stellar designs I received. From a distance the check shirt looks straightforward, but the fibers in each square and of each oval in the other shirt are somehow 3-D, not a flat part of the weave. Her art always reveals more the closer you look.
“Sometimes there’s so much beauty in the world…” (American Beauty)
YouTube finally got around to recommending Bill McClintock’s mashups to me. A lot of the enjoyment comes from bringing out the strong melodies underlying bombastic metal performances by pairing them with disco/pop/R&B songs; unfortunately, I’m not familiar with most of the Judas Priest/Slayer/Megadeath headbangers forming one half of the mashup.
Surely for the average pop fan “You Make September Fun” by Fleetwood Fire is his magnum opus, absolutely incredible. The way the songs blend is perfect; hearing Maurice White’s (RIP) perfectly-timed “Never a cloudy day, yow!” leading into the chorus feels like it must have been recorded in the same studio.
Commenters often claim “It’s better than the originals!” It’s intriguing that someone gluing two songs together can engender such appreciation. It sounds so good because you bring your familiarity with both originals to the combination. The absence of the expected, replaced by the unexpected but familiar, maxes out the predictable-unpredictable audio pleasure circuits in your brain.
But I guarantee someone unfamiliar with both originals would prefer them to this sensational mashup. Where’s the incredible brass from “September“? Where’s the soaring “belie-ee-ee-ee-eeve” chorus that Christine McVie (RIP) sings on her own song “You Make Loving Fun“? The towering originals put them in your brain, and they accompany the mashup even in their absence.
Have the AI do it, but lazily be filthy
With AI music generators you can imagine a mashup and an AI will fabricate it for you. A guilty juvenile pleasure was Obscurest Vinyl‘s combination of early 1960s pop/R&B styles with filthy lyrics, summed up by their singular “I Glued My Balls To My Butthole Again” by the Sticky Sweethearts.
It’s a decent song, elevated by the delicious word “again.” I commented (roughly, since Mr. Vinyl removed all YouTube comments, which were mostly of the form “This was playing at the high school dance and inspired my grandparents to conceive my mom”)
George Santayana wrote “Those who cannot remember the past are condemned to distend their sphincter, again and again.”
Another sickly strong song is Now I Gotta Set a Titty on Fire.’ I not only transcribed the lyrics on Genius as my small contribution to organizing all the world’s knowledge for posterity, I also applied my scholarship-winning Oxford-educated powers of literary analysis to some of the lyrics; click the shaded lyrics to admire my exegesis.
Off-beat lyrics from humans and AI
As you can tell, Obscurest Vinyl seems really angry! I hope writing or prompting lyrics for songs titled “You Look Like You Could Use a F**kin’ Lamp” and even worse are cathartic for him/her/them. They’re unlike the essentially good-natured YouTube channel There I Ruined It which I think uses AI to assist in its mashups. Its greatest achievement is Elvis Presley singing the “I like big butts and I cannot lie” lyrics of Sir Mix-A-Lot’s “Baby Got Back” to the tune of “Don’t Be Cruel”, but it has been cruelly removed from YouTube “due to a copyright claim by a [humorless] third party.”
A month after I wrote this in October 2025, AI generated a chart-topping country hit, “Walk My Walk.” As with visual art, I prefer the bizarre stream-of-machine-conscious that early AI generated in the good old days of 2020. Today’s AI can generate convincingly formulaic bro-country lyrics
Been beat down, but I don’t stay low Got mud on my jeans, still ready to go Every scar’s a story that I survived I’ve been through hell, but I’m still alive
but they don’t hold a candle to Rick Astley-bot spitting truths back in 2020 “You wouldn’t get this spaghetti on a guy… Kiss the boat Denny I’m Satan’s pirate arrr”, and the Bob Dylan-besting “You know the rules and so you have to die.”
Old wine in new packaging
Before easy mashups, musicians would actually have to record new versions of songs. There have been easy-listening versions of rock songs for a long time, and everyone in every genre recorded Beatles songs in the 1970s. Ted Templeton (who apparently isn’t the fantastic producer Ted Templeman), recorded Trill it Like it Was by The Templeton Twins with Teddy Turner’s Bunsen Burners, an album of rock songs played by a 1920s tea dance band and double-tracked crooner. It’s amusing for a few songs.
The excellent post-punk singer-songwriter Joe Jackson mashes up his own biggest hit “Is She Really Going out with Him?” I’ve seen him play it in concert as a capella doo-wop, brass band, and a bossa nova swing tune.
Why is shopping at Amazon so awful? It presents dozens of brands you’ve never heard of, and appallingly bad filtering options. And since 8% of the 1-star reviews are “It broke after X weeks”, let me filter for products by length and quality of warranty! I complained about the brain-dead-ness of its “Rufus AI” but the generally terrible experience applies even without AI getting it wrong.
We bought a Cuisinart Perfectemp cordless electric kettle years ago. Pretty good, but:
The water level indicator is behind the handle, hard to view, eventually gets milky and even harder to read.
The hole that lets the water flow into the indicator gets clogged so the water level doesn’t match the water level in the kettle.
The hole and the water level indicator are impossible to clean.
Shaking the kettle to get the water level to equalize may have caused the kettle to leak from the bottom after years.
Filter fiasco
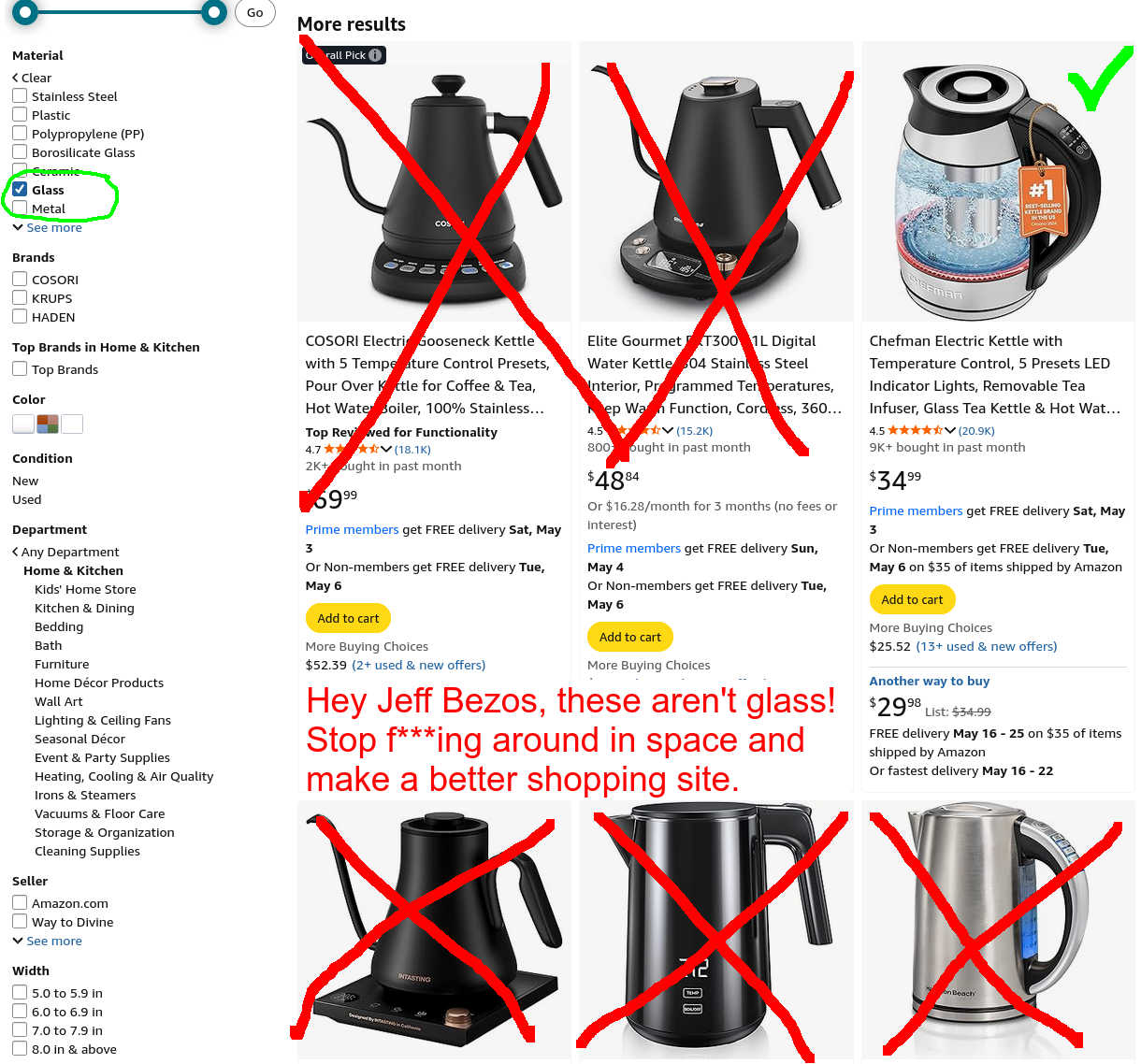
The separate water indicator. is stupid Just give me a glass kettle so I can see the water level! So let’s go to Amazon and shop for a glass kettle. Search for “electric kettle temperature control”, get over 1,000 results. So use the handy filter to filter for Glass, and most of the results are still not-glass kettles. Useless!
Warranty ought to be a mark of quality
Alright, so I’ll just visually scan for glass electric kettles. There are dozens. Are Brightown, Chefman, Comfee, COSORI, Elite Gourmet, Magic Mill, and NELO reputable companies making quality goods? Who knows? Click on 1-star reviews and there are plenty of people and/or bots paid by competitors complaining that the product broke in X weeks. So which companies stand behind their product with two-year or longer warranty? Amazon usually provides the useless and probably illegal cop-out:
Please contact the seller directly for warranty information for this product. You may also be able to find warranty information on the manufacturer’s website.
Reading more reviews, it seems many people give up and believe after the return period expires, there’s nothing they can do. All products have warranties, and your credit card probably doubles the warranty period. But it seems even reputable companies like Bodun and OXO fob off customers with requirements like “demonstrate proof of purchase to the company you purchased it from.”
On the flip side, with generative AI it’s trivial to make “cameraphone picture of a crumpled receipt for a Cuisinart kettle for $58.75” and even make a “shaky phone video demonstrating that a kettle is broken.” So I have some sympathy for manufacturers trying to stem the tide of returned goods. But companies should want to interact with customers in order to improve their products! Making and selling products is so broken in the 21st century; the gulf between people begging for a “KEEP WARM” setting on the kettle that defaults to OFF and the Chinese factory that cranked out a batch of 5,000 kettles four months ago is vast.
aarke! An exception
Clean water and less plastic, from a real company
We don’t waste money on bottled or canned water, instead we drink filtered tap water. Brita is OK but the plastic pitcher gets scratched and worn, the plastic lid breaks, and throwing a plastic filter in the trash every two months or so is dispiriting. We found aarke selling a glass water pitcher with a stainless steel filter that you refill, thus a lot less plastic. It seems high quality, and the company has actual customer service. I let them know about a typo in the manual, and a human being replied. Amazing!
Unfortunately, aarke’s kettle is double-walled stainless steel (and costs €250, and the excellent 5-year warranty only applies in the E.U. or UK).
For some reason San Francisco Art Fair thinks we’re high roller art buyers (even though we’ve never brought a painting home for more than $500) and offers us “VIP” tickets. (Though this reminds me of the “Las Vegas” episode of the Modern Family sitcom in which Jay Pritchett is conceited to get a room on the “Excelsior” penthouse floor of a Las Vegas hotel, until he realizes there’s a floor above him for “Excelsior Plus” black card members.)
There’s so much art on display by galleries that Sturgeon’s law ensures a lot of great fine art amongst a deluge of art trying so, so hard to have commercial appeal. The AI summary of the latter would be “A circular lenticular artwork made out of feathers, of a tasteful nude diving into a Los Angeles swimming pool.”
The clothes that some people wore for the opening evening were beautiful. It’s rare to see anyone well-dressed in a city where the official uniform is black vaguely-sporty wear. And not just women in dynomite dresses and fabrics; I saw several artsy men wearing pink sportcoats with their Bluebirds, also someone wearing an enormous couture puffy jacket and another wearing an Afghan coat that look liked a custom carpet.
There’s no way I could discern all the artworks that were in Sturgeon’s 10%, let alone give them the attention they deserve, but here are images of some that I noted. Given time, dozens more could and would have seeped in and affected me. Overall favorite: “Laundromat” Liu Tianlian Favorite sculpture: “Big Bang” Robert Brady Favorite abstract: “Just Let Them” Isabelle Beaubien Honorable mentions: John Belingheri, Georgia Hart, Trenity Thomas.
Liu Tianlan’s big ink and color on silk “Laundromat” at the booth of Yiwei Gallery (Instagram link, she’s not on the gallery’s own web site yet) was KA-POW. It’s the movie “Everything Everywhere All at Once” squeezed into the movie’s laundromat. Wowzer. No picture does it justice, the 9-foot long painting’s polyptych wood framing (missing from this image) is great. This artwork alone is worth a visit.
Robert Brady’s Instagram feed has a 2-year-old pic of “Big Bang” before it got the ash treatment. They grow up so fast.
Isabelle Beaubien’s “Just Let Them” at Spence Gallery (F07) was my favorite abstract painting. A lot of art at the fair was circular to be different and commercial, but this enormous (120 cm/48 inch diameter) acrylic and resin record has to be that shape. I have no idea how hard it is to execute.
John Belingheri at Andrea Schwartz Gallery had “Jade”, a striking painting of a green loopy grid. It’s reminiscent of the calligraphic loops of Brice Marden (1938 – 2023) but more a city of undulating connections – like San Francisco. It doesn’t work at all on a screen, this 5-foot square canvas has to be human-sized in the room with you.
Trenity Thomas at Ferrara Showman Gallery had some strangely flat humorous paintings, this is “Take Me With You”, 2024. What’s with the lemons?
Also by Trenity Thomas, “To Be Held”, 2023. Another lemon, and look at the dog’s mouth!
Georgia Hart at Quantum Contemporary Art paints great thick impasto skies, e.g. “Sligachan, Scotland.” You can’t get that from an AI-generated 2D array of pixels.
Ones that got away
One artist had a great seascape in graphite, another had seascapes made by etching colored paper. “Majestic indifferent oceanic grandeur” is an easy subject to add some heft to your work, but both were very well executed.
AI art is coming
In endless online debates about whether AIs are creative (yes, they are) I point out that a pixel grid that presents an image of an artwork is not a fine artwork that exists in the world! Go buy real art to put in your room and hang on the wall. But robots are coming for “the thing” as well. The 2rt booth (in addition to the commonplace lenticular art) had “Aiden Noir” robotically painted photos, that you can also scan with an app to turn into short panning videos. Also there was a wall with some Augmented Reality Art “paintings” on it. There wasn’t much information about these, maybe they were snuck into the fair to avoid pearl-clutching condemnation from real human artists and the galleries that represent them.
If you’re trying to make commercial art that people want to hang on the wall, an AI that’s ingested billions of images and gigabytes of art theory and critical writing is going to meet your customers’ wants. I love supporting the creativity of human artists – #respectArtists! – but I would also love someone or something to execute the wonderfully inventive set of pixels that Craiyon AI came up with three years ago (when it was just a callow adolescent autoregressive transformer) in actual oil paint on a large canvas.
paint me “Painting of a black cat with white markings sitting on a chair by Franz Kline”!